Pricing Pain Point #1 - Data issues


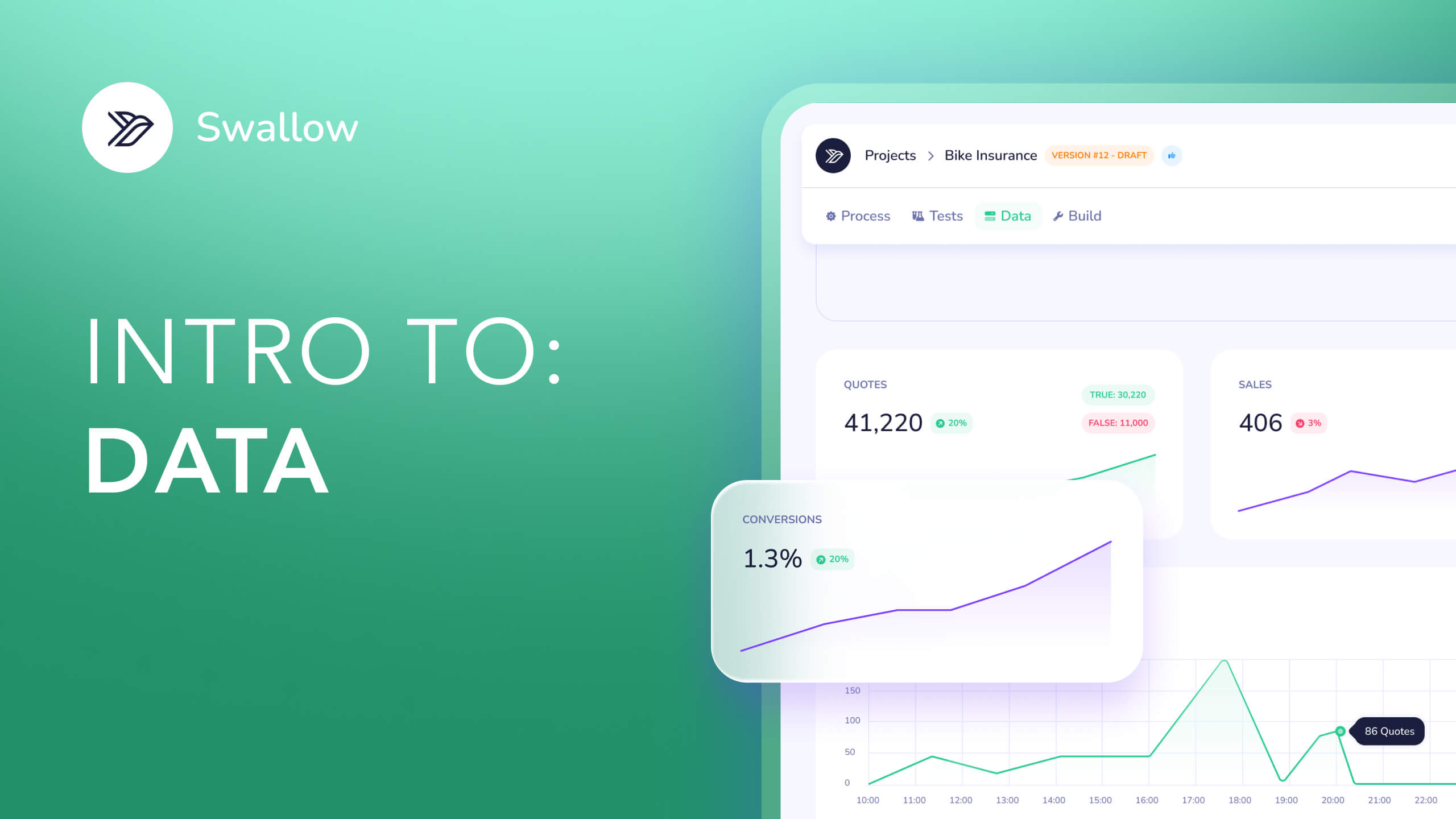
Underlying all pricing strategy is data, whether it be on the market and competition or a company’s own quote, sales and cost data. Collecting this data and using it to inform future pricing decisions is one of a pricing team’s key objectives. For example in insurance, where many product lines have become commoditised, continuous iteration and running experiments is often the best way to find the optimal price for a product, one that balances growth and profitability. However, in order to do this, a business must have clean usable data on these pricing changes and their outcomes.
Through our team’s experience leading financial services businesses and our conversations with more than 100 pricing and technology leaders, we’ve identified the biggest challenges facing their teams when it comes to data.
From our conversations with pricing and technology leaders, 56% of them talk about data-related challenges as a significant pain point for them and their team
We believe there are many opportunities to improve how we work with data in pricing. We’ve focused on 3 areas to solve with the first version of our platform:
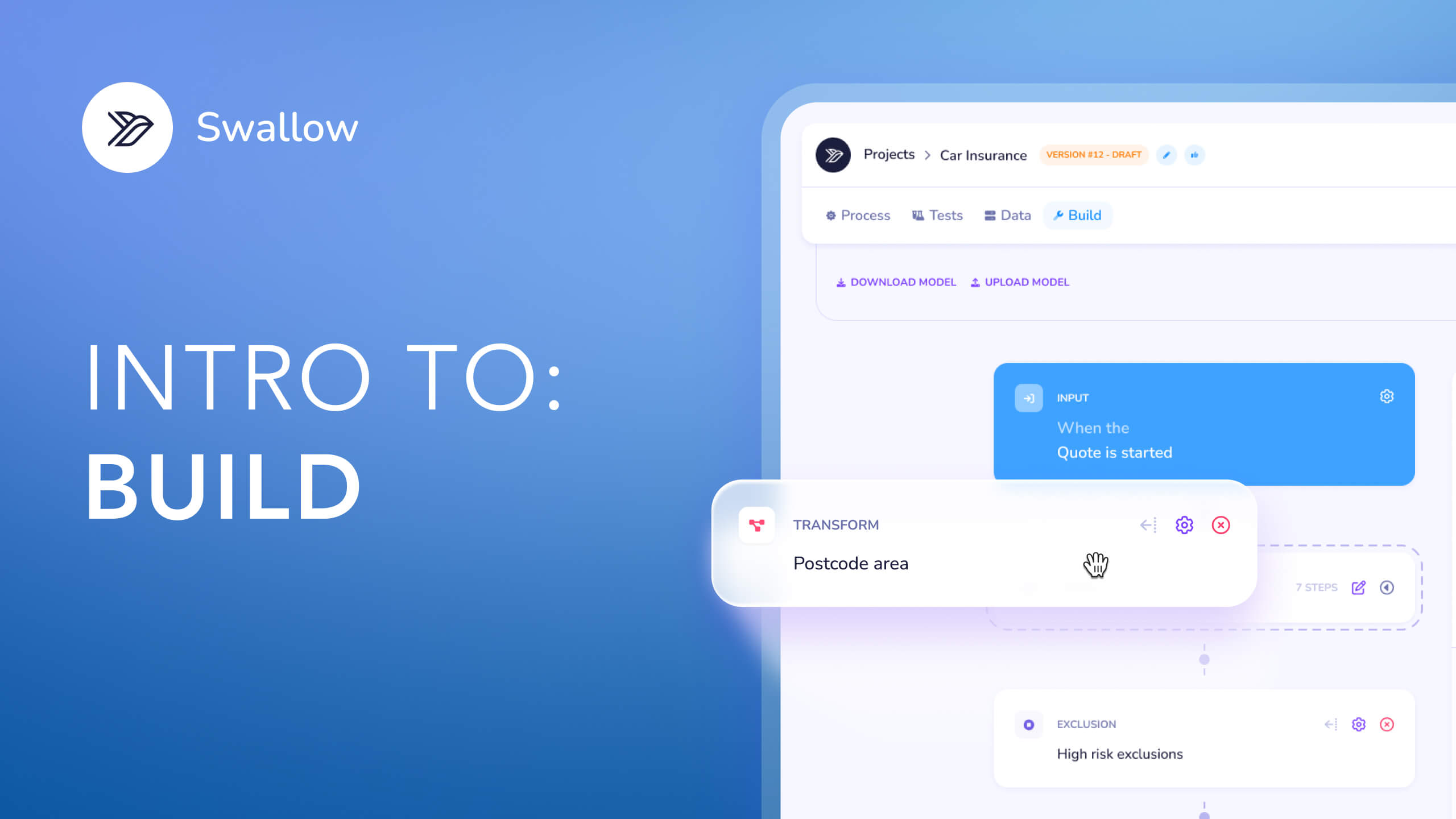
Swallow Data is just one of 4 initial products we’re releasing on our platform, please see our other posts for more on Testing, Publishing and Data.
Powerful apart but awesome together. Transform how you price.
We’d love to hear more about your data pain points, so if you’re keen to share, or would like to try out the Swallow platform - please do get in touch at contact@swallow.app