The $1 Trillion Corpus That AI Cracked

Every US insurance product passes through SERFF (the System for Electronic Rate and Form Filing) before it reaches the market. Every actuarial memo, every rate change, every Excel rater, every rule manual. Twenty-five years of it.
It is the richest pricing dataset in US property and casualty insurance. It has been technically public for two decades. And it has been functionally unusable for almost as long.

Swallows SERFF platform is an agentic infrastructure that reads, structures, and rebuilds the entire US regulatory filing corpus, and turns it into something insurers can actually use.
The corpus is massive and no one has read it all. Furthermore, researching and comparing it year by year is very time-consuming.

The information is there. Competitor rates, underwriting logic, discounts, surcharges, eligibility rules, state-specific variations - all of it, sitting in PDFs and spreadsheets scattered across jurisdictions, in formats that vary by state, by carrier, and by year.
To extract pricing logic from a single competitor's filing takes a senior actuary somewhere between days and weeks. To do it across a market is multi-quarter work. By the time the analysis is done, the market has moved on.
Most teams don't lack access to the data. They lack the ability to use it.
Reading SERFF is not a chatbot problem. It's not a search problem either. It's an agent problem.
To answer a question like "How are insurers filing wildfire deductibles in California this cycle?" - let alone "Replicate this competitor's homeowners rater" - a system has to:
That's long-horizon, tool-using, verification-heavy work, orchestrated across dozens of model calls per task. It's exactly the shape of problem that frontier models couldn't reliably handle six months ago.
The rater conversion step in particular - taking forty tabs of nested VLOOKUPs and conditional logic and producing code that prices identically to the original - sat just beyond what models could hold together.
That has changed!
Three things, today, on the California corpus.
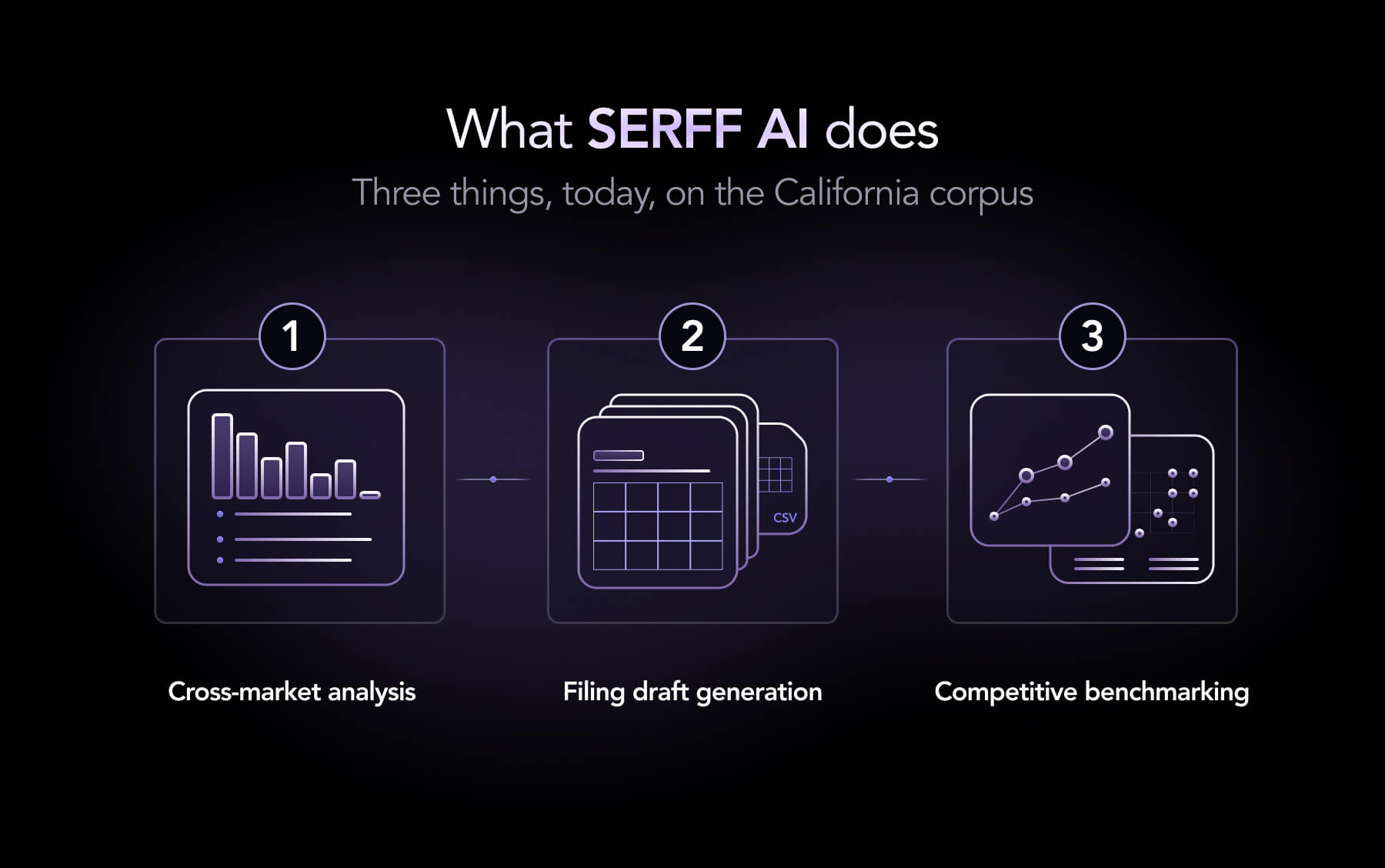
Ask: "How are insurers filing wildfire deductibles in California this cycle?"
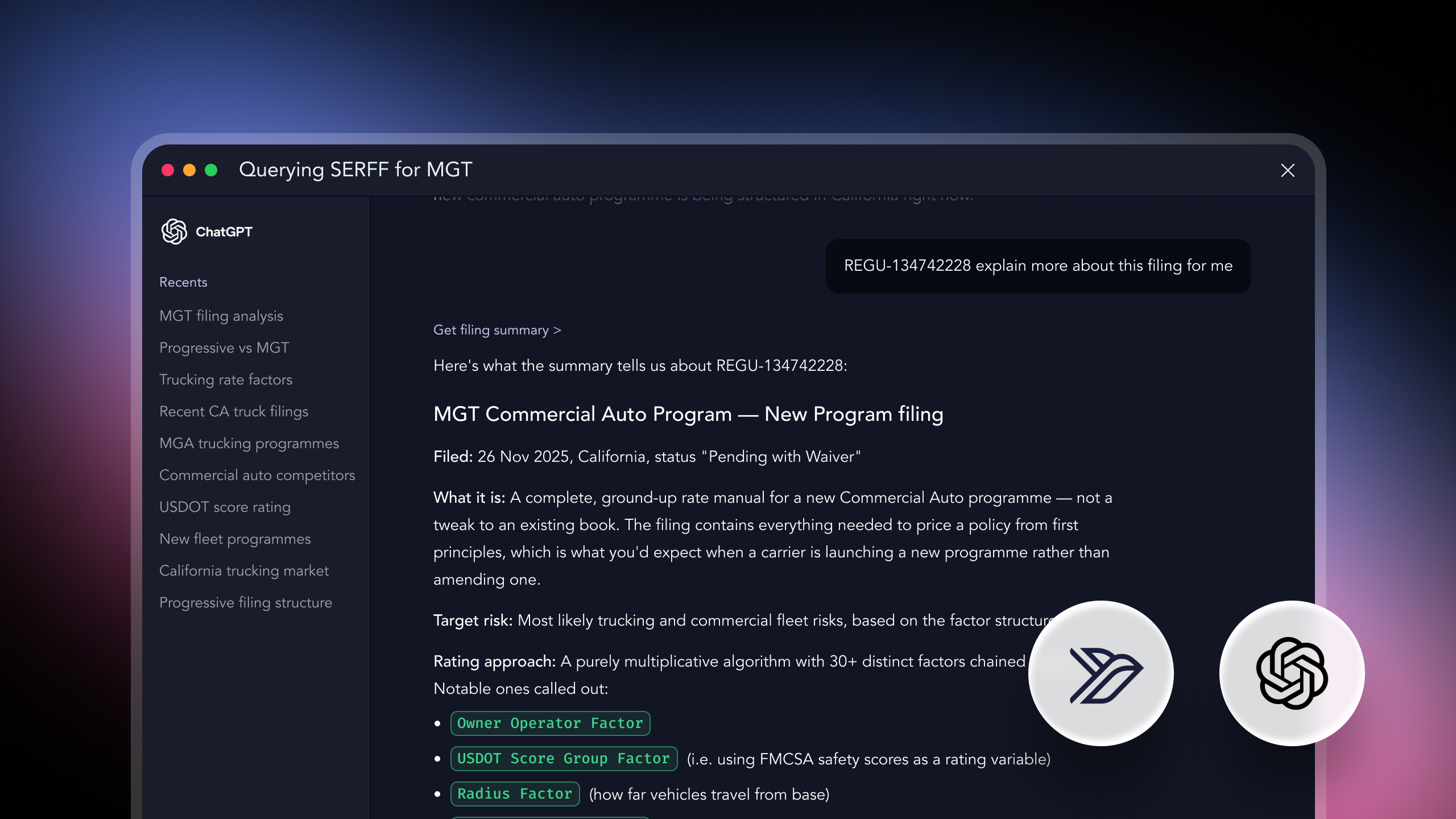
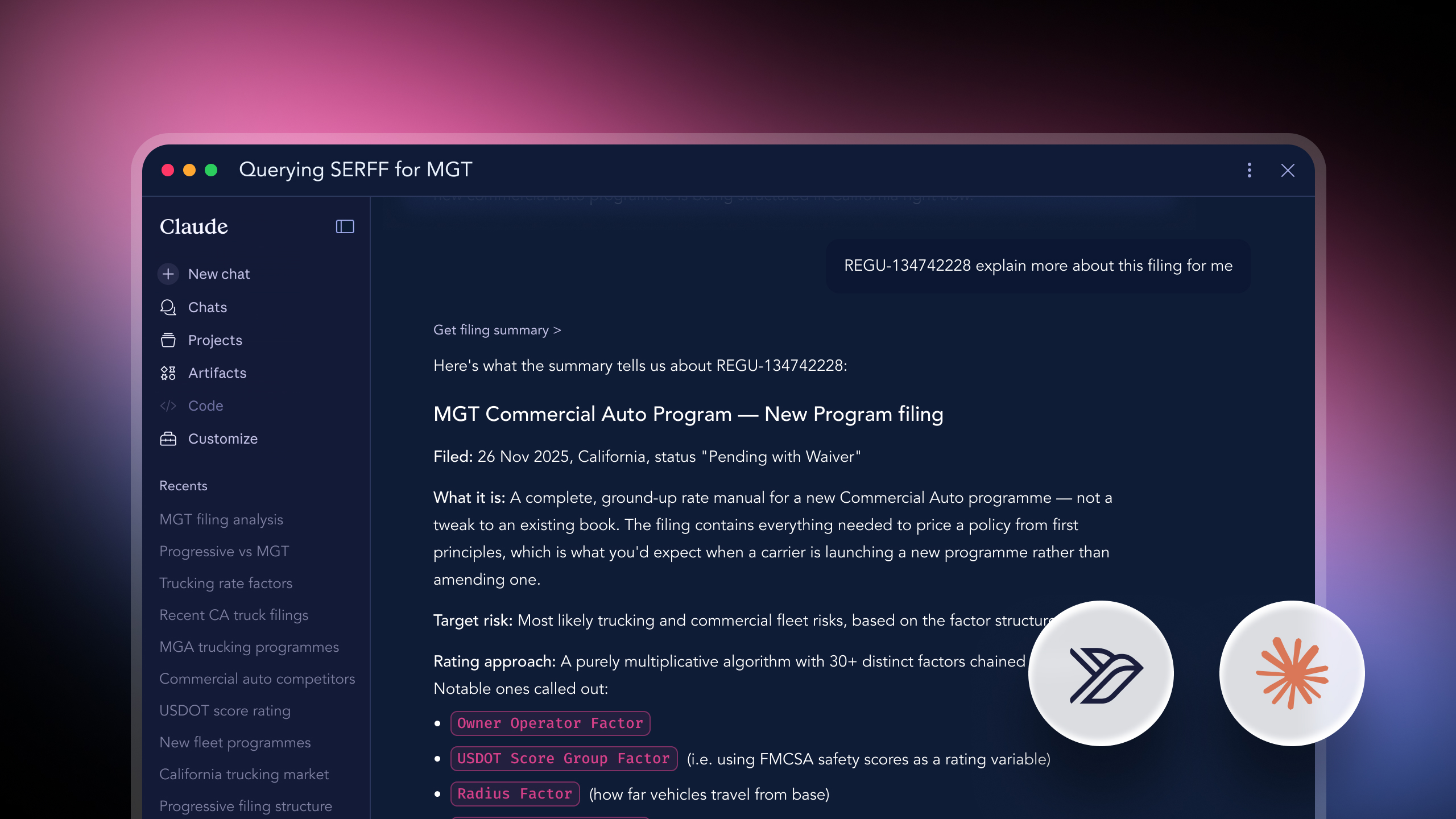
You get a structured answer across every filing - relativities, base rates, eligibility rules, regulatory commentary - synthesised into a comparable view. What used to be a multi-week project for an actuarial team becomes a query.
Ask: "Draft our California homeowners filing."
You get a complete rate filing package - actuarial memo, rater, exhibits - built on precedent that has already cleared the CDI. Not template language. Real, defensible, regulator-ready content built from 25 years of approved filings.
Weeks of work, not months. A fraction of the cost.
Ask: "Benchmark my California homeowners book against every competitor."
You get 2,500+ test quotes priced through every rival's rater. Where you win, where you lose, by how much, and why — at the policy level, with the underlying logic exposed.
This is the work pricing teams have wanted to do for a decade and haven't been able to.
The purpose of SERFF AI isn’t to simply read filings. It’s to transform them into models and provide pricing teams with everything they need to work with those models.
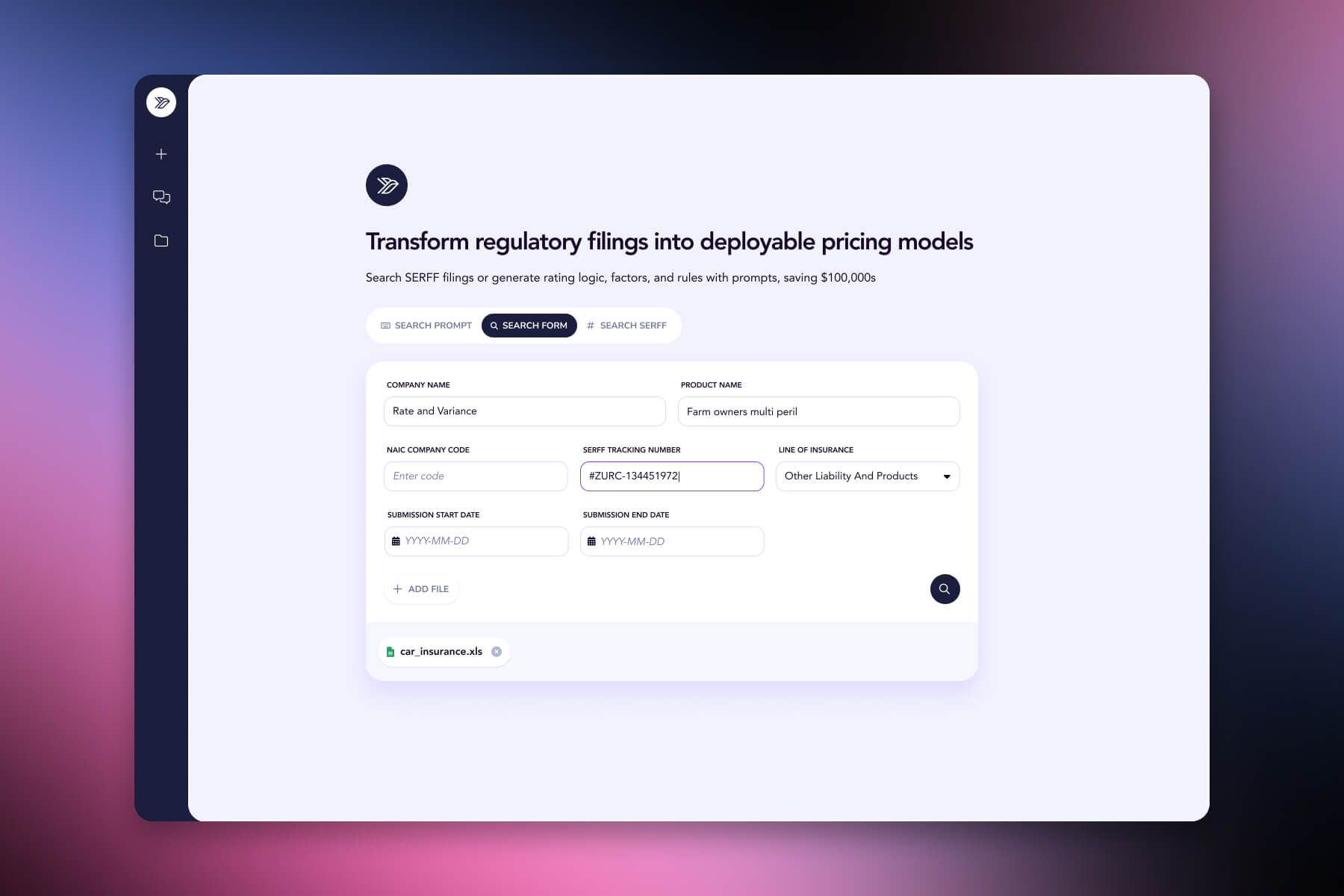
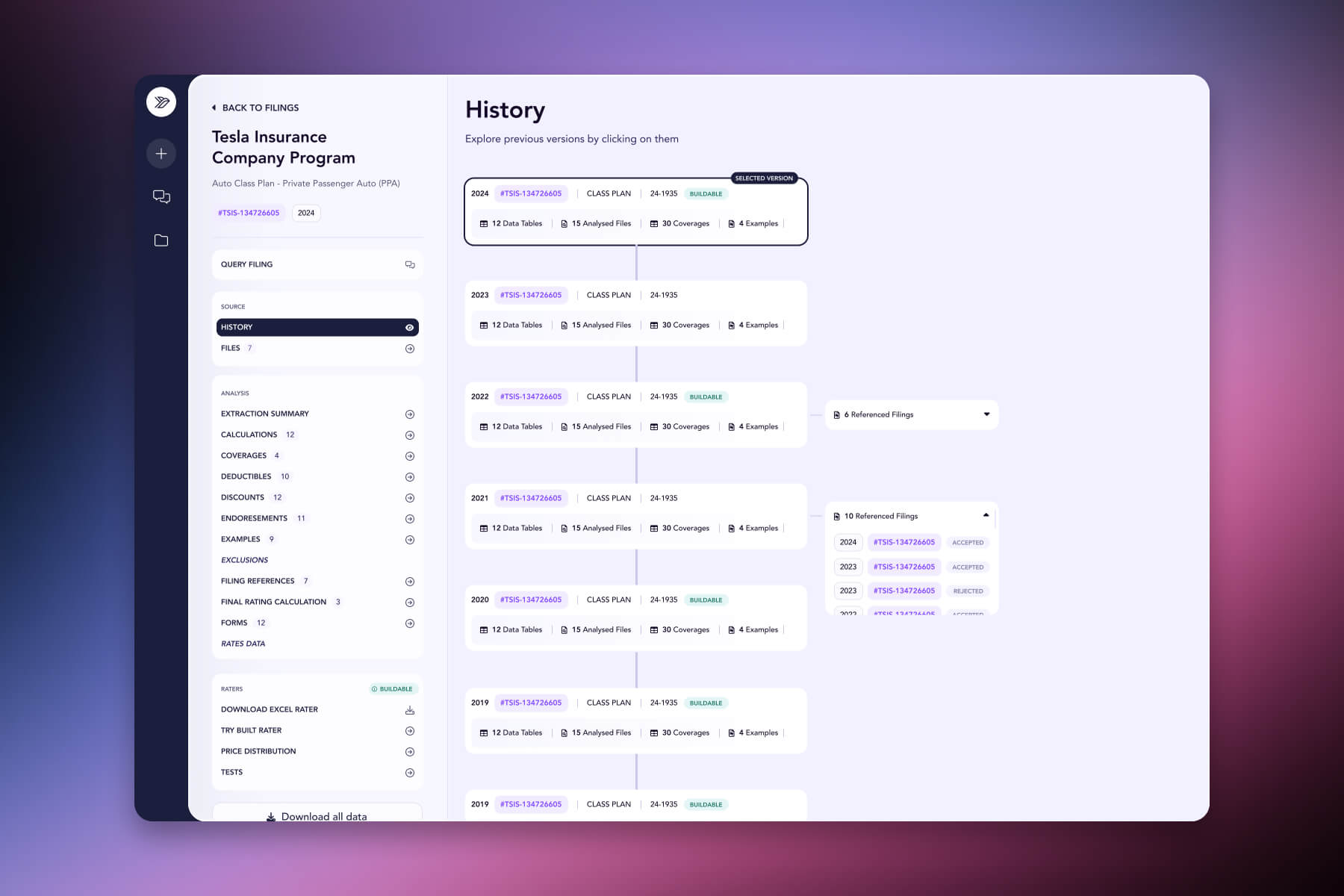
Corpus access. Every California filing since 2005, fully ingested and queryable. Search by carrier, line of business, peril, filing type, or date range - or semantically, in plain English. Every result links back to its source SERFF tracking number for verification.
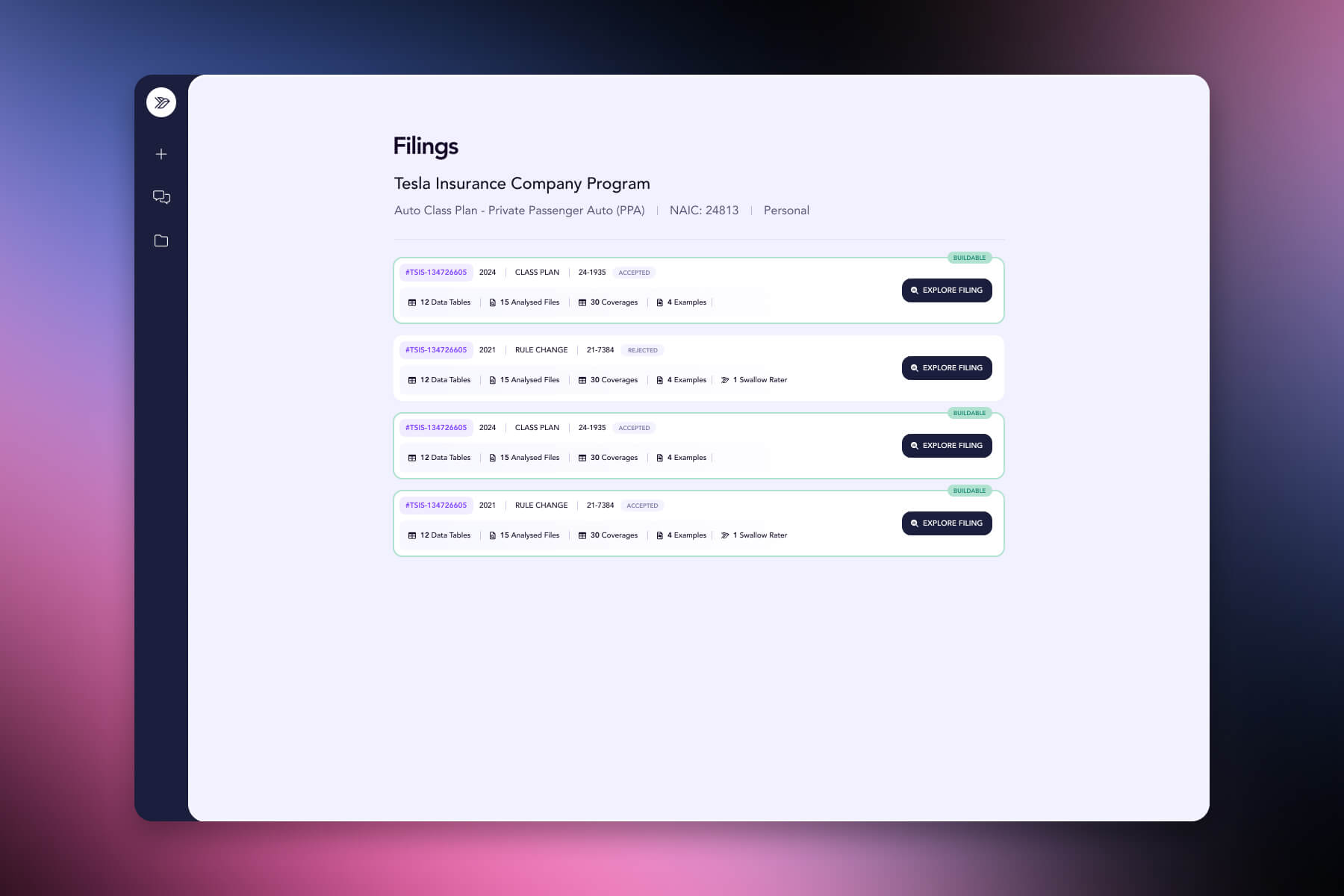
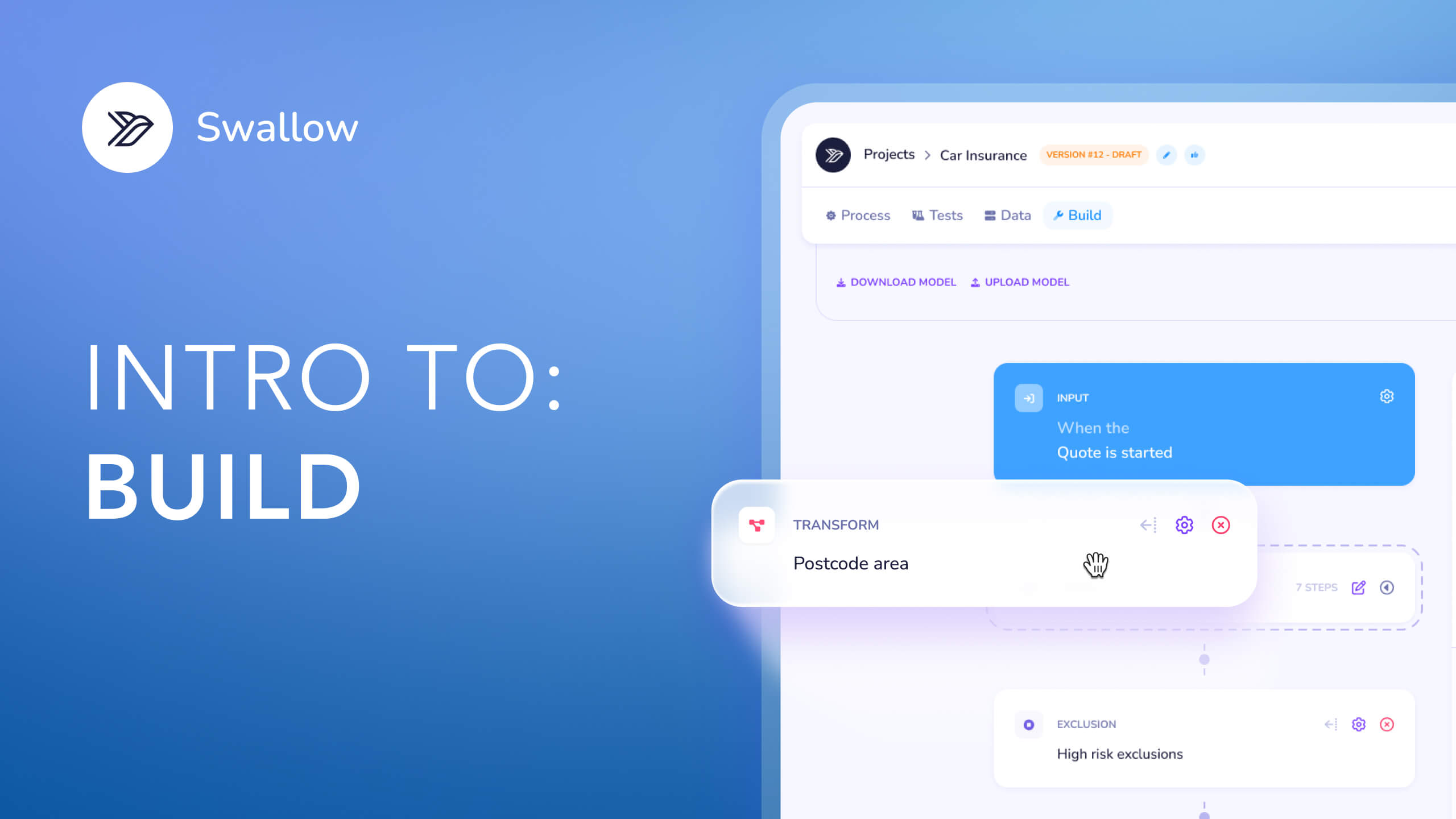
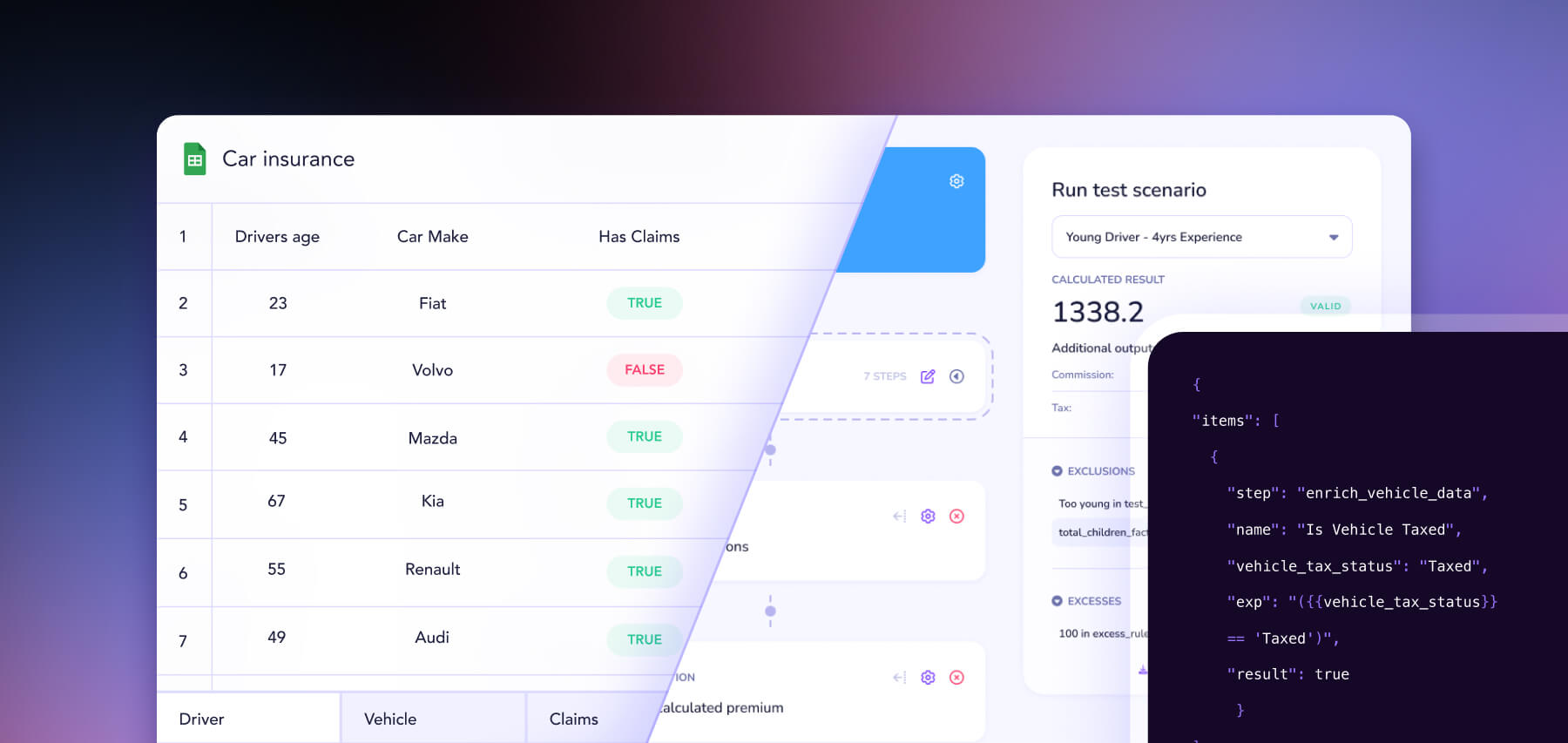
Filing raters. Any filing in the corpus can be converted into a structured, executable rating model. Variables, factors, tables, eligibility rules, conditional logic - all translated into Swallow's JSON pricing schema and validated end-to-end against worked examples in the source filing.

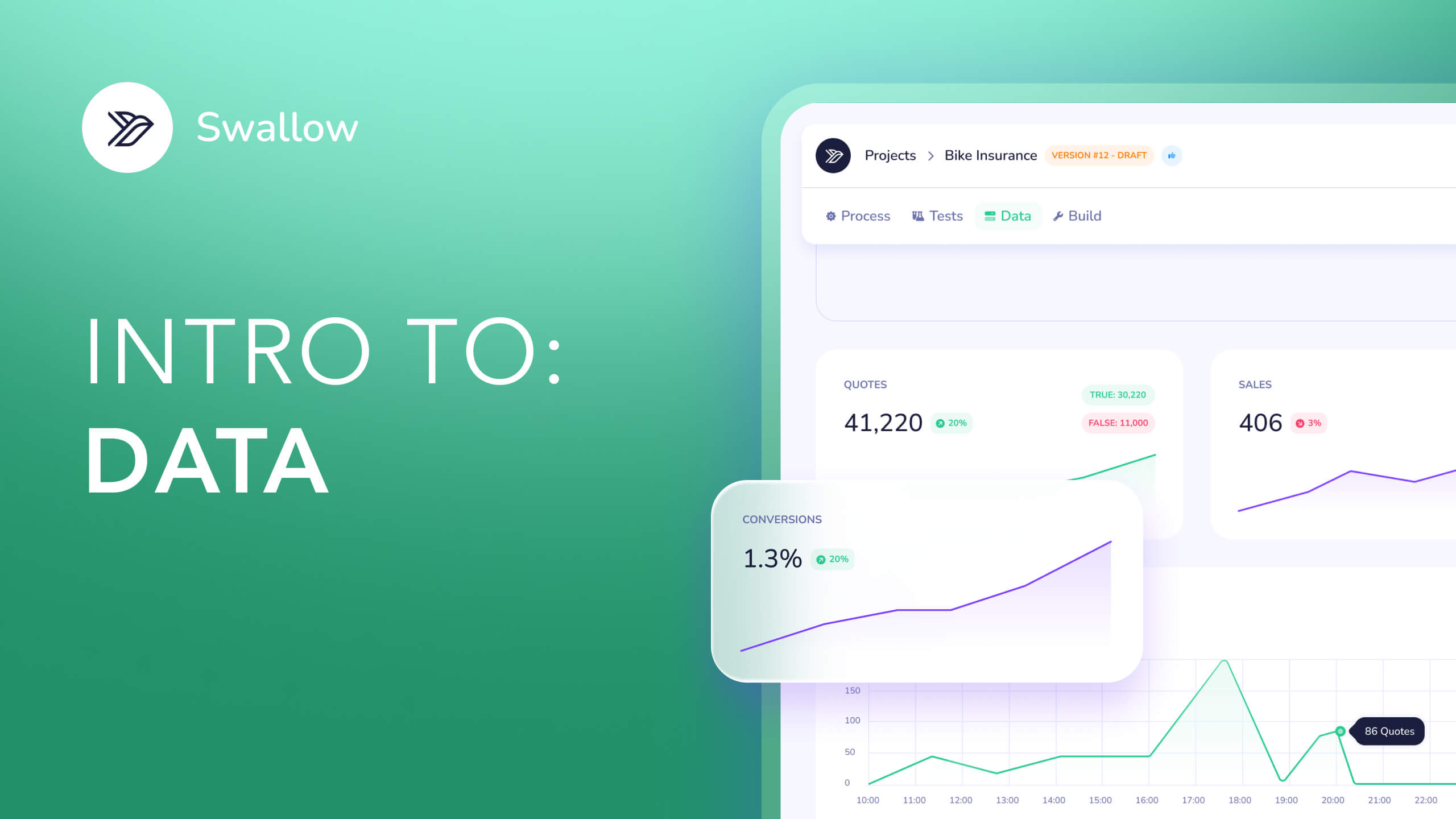
Cross-filing analysis. Compare any number of filings on any dimension. How does Carrier A's wildfire deductible structure differ from Carrier B's? How have a competitor's protective device discounts changed across their last five filings? Structured, comparable, exportable.
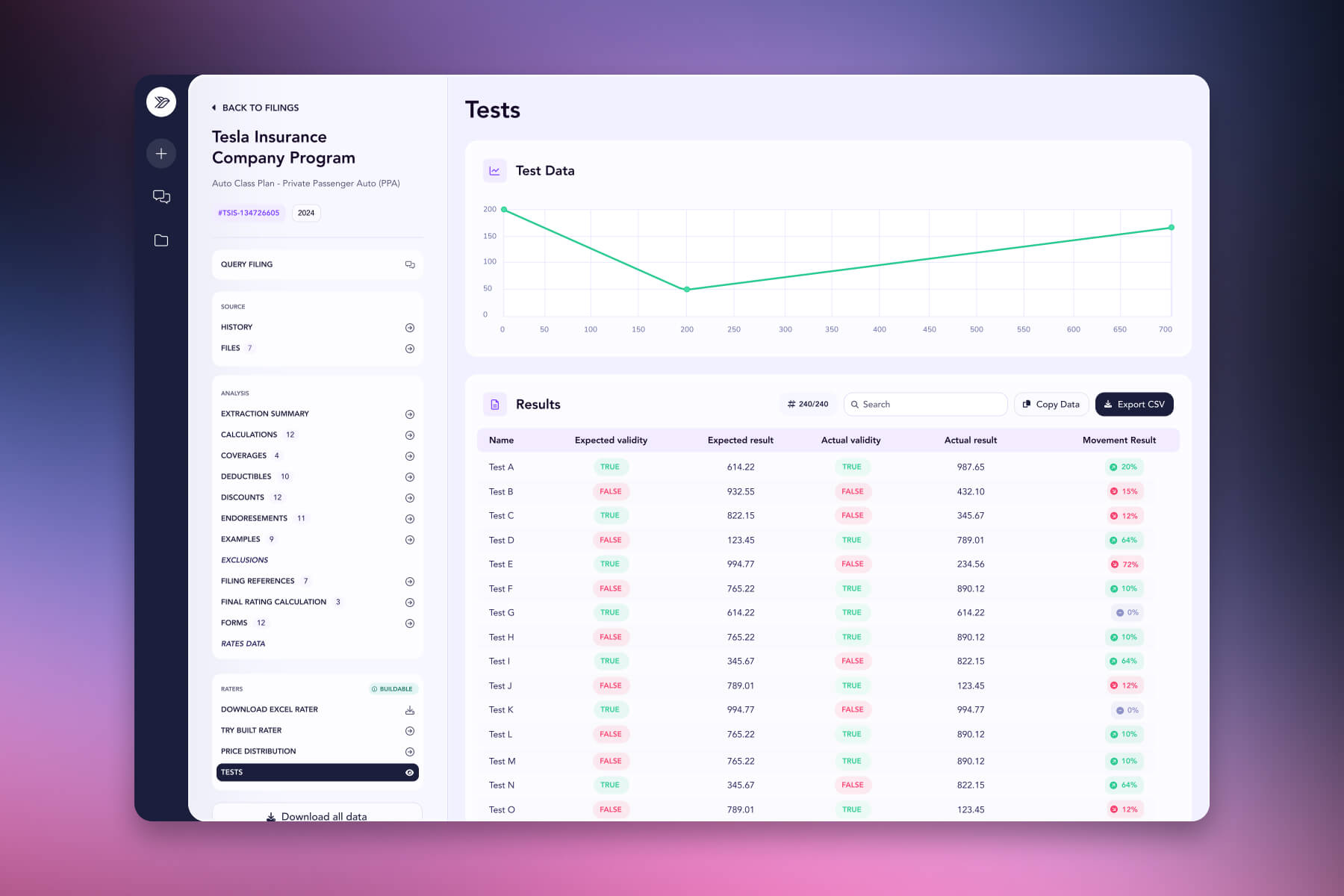
Competitive benchmarking. Run your book of business against every competitor's rater at scale. 2,500+ test quotes, full price decomposition, win/loss analysis at the policy level - with the underlying logic exposed, not inferred.
Filing draft generation. Produce regulator-ready filings - actuarial memo, rater, exhibits, supporting documentation - built on precedent that has already cleared the CDI. Every substantive claim cited back to its originating filing.
Production deployment. Export any rater to Swallow's pricing engine. Live API in minutes, embedded quote forms in hours, integrated into your distribution stack the same day. The same infrastructure that powers production pricing for our existing customers.
The naive approach - "throw it all in a long context window and ask the model" - doesn't work at this scale. The corpus is too large, the formats too varied, and the verification requirements too strict.
SERFF AI is a pipeline of specialised agents, each doing a narrow piece of work that frontier models can do reliably, composed into something more capable than any single model call.

Filings arrive in mixed formats - PDFs, Excel raters with dozens of tabs, Word documents, scanned documents requiring OCR. Each document is classified by type (rater, memo, exhibit, cover letter, objection response) and parsed accordingly. Excel raters get special treatment: the structural logic is extracted programmatically, but the semantic intent - what each tab represents, how factors are layered - is interpreted by a model with access to the broader filing context.
Documents are chunked using a hybrid strategy that respects both semantic boundaries and structural ones - a rate table doesn't get split halfway through. Chunks are embedded using models tuned on insurance regulatory text. Generic embeddings underperform meaningfully on this domain.
For any task, an orchestrating agent decomposes the question into sub-queries, runs them across the corpus, reconciles the results, and decides whether more information is needed. Filings frequently disagree - the same carrier's California product can show different protective device discounts across two adjacent filings - and reconciling those contradictions is part of the work.
The output depends on the task. For analysis, it's structured comparison data. For rater generation, it's JSON pricing configuration that runs natively on Swallow's pricing engine. For draft generation, it's a filing package with every substantive claim cited back to source.
This is the step most AI systems skip. Every generated rater is run against worked examples buried in the source filing - the rate change exhibits, the sample policies, the test cases regulators required. Premiums must reconcile to within tolerance. When they don't, the failure feeds back into the rater-generation agent, which iterates until reconciliation is achieved or flags the discrepancy for human review.
This last step is what makes the output usable. A rater that looks right is worthless. A rater that prices identically to the original, on every test case in the filing, is a rater you can deploy.
This couldn't have been built a year ago. Probably not even six months ago.
Three things converged:
None of those alone is sufficient. Together, they make SERFF AI possible.
We've started with California: every filing since 2005, every rater, every rule, fully ingested and structured.
California is the hardest US filing jurisdiction. Prop 103, the FAIR Plan crisis, the wildfire exposure, the politicised rate environment — building for California means building for the worst case. Once that's solved, the rest of the country becomes a question of throughput rather than complexity.
Other states follow.
The US P&C market is ~$1 trillion. The teams that win it will be the ones that can read regulatory data faster, build pricing models quicker, and deploy changes without friction.
We're looking for US insurers, MGAs, and reinsurers to help shape what we build next.